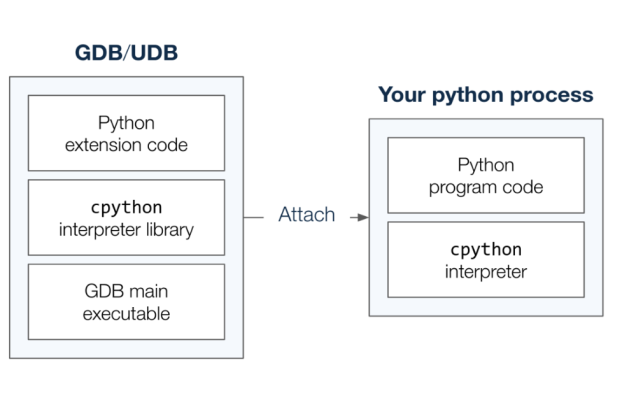
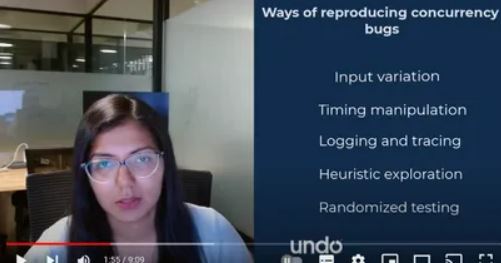
RESOURCESUndo Resources Shape All types (139) Blog (111) Technical Papers (6) Videos (22) Blog 111 items BlogResources [New Release] for UDB and LiveRecorder 7.2 for C/C++ March 13, 2024 BlogResources How I debug Python code with a Time Travel Debugger January 22, 2024 BlogResources [New Release] UDB and LiveRecorder 7.1 for C/C++ December 8, 2023 BlogResources Valgrind Quick Reference Guide: How to Use Valgrind to Detect C++ Memory Leaks December 6, 2023 BlogResources How to Debug Linux C++ Race Conditions December 4, 2023 BlogResources [New Release] UDB and LiveRecorder 7.0 for C/C++ September 14, 2023 BlogResources Debugging a complex multithreaded codebase like SAP HANA September 1, 2023 BlogResources Debugging concurrency bugs in multithreaded applications January 12, 2023 BlogResources [New Release] UDB and LiveRecorder 6.12 for C/C++ January 11, 2023 1 2 … 12 13
![[New Release] for UDB and LiveRecorder 7.2 for C/C++](https://undo.io/wp-content/uploads/2023/05/image-51.png)