Resources
Undo vs rr – What’s the Difference?

One of the most common questions we get when engineers are trying out Undo is: “How is it different from the rr debugger?”. A complete answer to this question would be long-winded, but there are two key architectural differences between Undo and rr that explain the majority of the differences between the two tools.
- Undo uses a software JIT binary translation to get the information it needs from the program being recorded; rr relies on CPU features such as performance counters and OS features such as seccomp.
- Undo records into an in-memory circular buffer and saves it afterwards; rr writes it directly to disk as recording happens.
There are pros and cons to these approaches which will be explored in this article, looking at a few key areas as listed below. In brief, though, rr is lighter-weight whereas Undo can be used on a wider range of platforms and programs and has more features.
- Feature comparison
- How time travel debuggers work
- A crash course in dynamic binary translation
- Performance
- Shared memory
- Hardware and virtualization support
Undo vs rr feature comparison
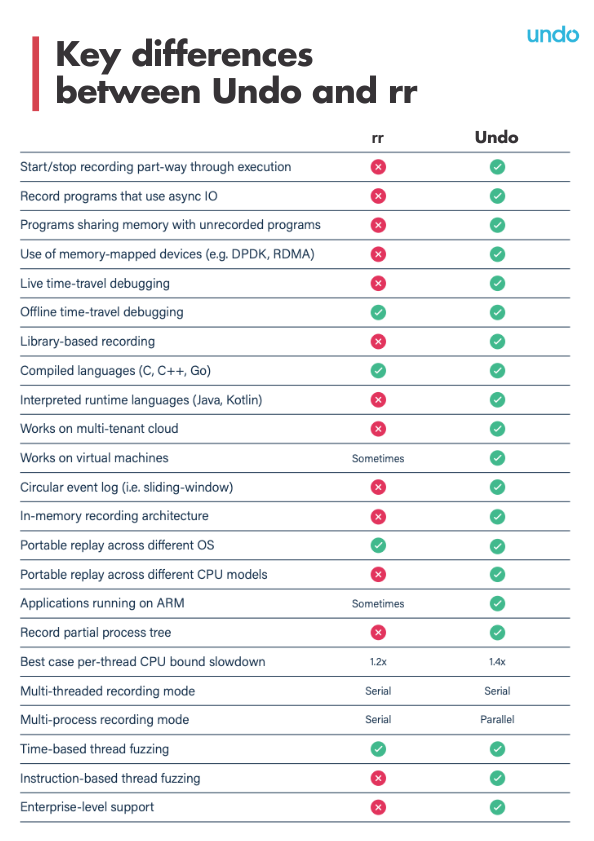
How time travel debuggers work
A time travel debugger can wind back the clock of execution to any point in the recorded program’s execution history – allowing you to see any piece of program state. Early attempts at implementing time travel recorded every state transition of the program’s execution, which was impractical in terms of slowdown and storage requirements for all but the smallest programs. Modern time travel debuggers recompute prior states using a snapshot-and-reexecution approach. To do this, three things are needed:
- A snapshot of the starting state of the application (i.e. registers, memory, and relevant operating state).
- A log of all non-deterministic inputs into the application. Non-deterministic inputs include data read from sockets or the filesystem, non-deterministic instructions such as rdtsc, asynchronous signals, and reads from shared memory.
- A precise measurement of program execution time.
Once you have these three things, the idea behind reversing to an earlier application state is conceptually simple. To get to an arbitrary point in the application’s execution history, go back to the starting state (or an intermediary snapshot) and re-run the program to the state point you want, feeding in non-determinism where required to ensure that the exact same code path is taken on replay as was taken at record time.
That means the replay engine needs to be able to mock up system call results, reinject signals at the right point in time, fake up the results of certain CPU instructions, etc. The method of achieving this record and replay approach is where one of the big differences between Undo and rr arise: dynamic JIT binary translation (Undo) vs performance counters, ptrace and secomp (rr).
A crash course in dynamic binary translation
Take a look at the following diagram, which represents a run of an application without Undo present.

Fig. 1
In this diagram, blue boxes represent code generated by the compiler. Each section of code ends with a jump to the next section; some blocks of code may have multiple places that they could jump to – as shown by the dotted lines.
The horizontal red line shows the current value of the process’s instruction pointer which is the code that’s currently being executed. As time passes, we end up with the situation on the right of the diagram. A certain code path has been executed (shown in dark blue), but even the code that wasn’t executed still exists in memory.
Next up, we see an example of what the same execution path might look like when running under the Undo recording engine (note: this is the technology that implements the record and replay functionalities in Undo).

Fig. 2
You’ve probably noticed that the light blue code from before, while still present, is never executed. Instead, the Undo Engine uses JIT binary translation.
This means that as your application is executing, the Undo Engine is reading the code that is about to be executed (the blue code), decoding it, and emitting new code (the green code) that is functionally identical to your application’s original code. But, it also records all the non-deterministic things that happen in your process and keeps a precise track of execution time (essentially, how many instructions have been executed).
When running with Undo, the code that’s generated by the compiler is never actually executed! Only the Undo Engine’s custom-generated code – which is derived from the compiler’s output – is run.
This is a very flexible approach, and is the key behind a lot of Undo’s functionality (e.g. shared memory support, portable cross-machine replay, etc.). The rr project is in some ways similar to Undo, but doesn’t use binary translation at all, instead relying on hardware and kernel features and execute code in a manner similar to the “without Undo” picture above. This means that rr can run “normal” code without having to inject an instruction decoder and JIT translation engine.
Performance
The main advantage of rr’s approach is performance: slowdown can be as good as 1.2x vs. native. When compared with Undo’s best-case slowdown of around 1.4x, it seems that rr’s approach is a clear winner.
However, for most real-world programs things get more complicated – rr needs to catch certain non-deterministic events (such as reading the timestamp counter) via hardware traps via the OS which are very slow. In short, your mileage may vary: on some workloads rr has better performance, and on others Undo does.
Shared memory
In the world of time travel debugging, shared memory is a particularly interesting source of non-determinism. Unlike most other non-deterministic events (signals, system calls, etc.), shared memory can have the effect of making any instruction that reads from it into a source of non-determinism.
The last value written isn’t necessarily the same as the next value read. Another process, the kernel, or memory-mapped hardware could have written to that same memory in between.
This isn’t ideal for recording a process’s execution history, and both rr and Undo have different solutions to this problem.
The first distinction to make is that rr records a process from the beginning of its execution. That is to say, it doesn’t support functionality similar to that of GDB’s attach.
This is advantageous in that it means rr always has control of the entire process tree and automatically follows fork() and exec() system calls. This means it records all processes in the process tree.
For memory shared between processes in the process tree, then, it’s possible to make reads and writes deterministic by serializing the entire process tree.
If only one process can write and read from shared memory at any one time, there can be no races and, so long as the scheduling of the processes is kept the same when replaying, replay will be deterministic.
There are a couple of drawbacks to this approach. Firstly the obvious one, is that the entire process tree is serialized. This means that any advantage from parallelizing the workload is negated when running under rr. The second is that memory shared outside the process tree is still non-deterministic. As a result, rr does not support shared-memory if the memory is outside the process tree.
Undo, on the other hand, does not have to record a process from the beginning of execution. Using a clever combination of instrumentation and the MMU on the host system, Undo can retranslate blocks of code that access shared-memory and store their non-determinism in the event log. This has the advantage of not requiring serialization of process execution, and working for memory shared outside the process tree, including DMA and asynchronous kernel writes.
Hardware and virtualization support
Undo’s approach is more flexible when it comes to supporting a wide range of hardware, virtual and physical. One of the hardware features that rr relies heavily on is Intel’s performance counters.
Unfortunately these aren’t documented very well, but they’re usually accessed via the linux perf API. As a result, hardware supporting these performance counters is required in order to make rr work.
You have to be careful, when provisioning machines in a large virtualized environment, to make sure that you get machines with performance counters enabled and hardware that supports them. For security reasons, many performance counters are disabled by default on virtual machines over concerns they may leak information about the host system to the guests.
This inability to run in virtualized environments is a significant (although not insurmountable) drawback when using rr. Because of this, we’ve put a lot of effort into making the Undo Engine work as well as possible in virtualized environments.
With the software ecosystem relying on virtualization as much as it does, this is a significant drawback when using rr. With Undo you can provision virtually any hardware you like – provided it has an x86 or ARM64 CPU – and expect it to work. Undo packages all the required software into a single binary and has no dependencies, making it easy to copy a single binary onto your machine and get started making recordings.
Conclusion
This article only outlines the biggest areas where rr and Undo differ; and even within these areas the advantages and disadvantages of the comparison depend heavily on the workload which is being recorded.
Time travel debugging saves developers a HUGE amount of time, so it’s a no-brainer. And whether you use rr or Undo, it doesn’t matter. Use whatever works for your application.
By Finn Grimwood, Staff Software Engineer at Undo