Fix your flaky tests problem
Eliminate flaky test failures with time travel debugging
The dirty secret in software development
82% of software vendors have experienced issues in production related to a previously seen but unfixed test failure.
[See this analyst research report]
This means that defects that are seen in test make it into production. Usually, this is because the test failure could not be easily reproduced, meaning that the root cause could not be determined. The same analyst report finds that 91% of software developers admit to having defects which remain unresolved because they cannot reproduce the issue.
In short, we are willfully releasing defective software, with known failures.
The causes of flaky tests
In the majority of cases, defects are hard to reproduce because they are intermittent. They stem from sporadically failing tests (aka flaky tests) that fail to produce the same results each time, e.g. they might fail the first time and pass the next, despite the execution environment being the same.
There are many causes of flaky tests, but broadly speaking, they can be caused by:
- non-determinism in the software under test
- or non-deterministic behavior in the tests themselves (use of non-monotonic clock, resource leaks, infrastructure dependencies, etc.)
Flaky tests are a smoke alarm. Until you have diagnosed the root cause, you cannot know whether that smoke is coming from your test or your product code.
The true impact of flaky tests
Flaky tests are one of the biggest hurdles in maintaining a reliable test automation framework.
Flaky tests are a developer productivity killer
Flaky tests are expensive to debug: engineering teams invest days, weeks, and sometimes months of effort to isolate the problem for root-cause analysis.
Worse, an outcome is never guaranteed.
Even if the reaction is to rerun the test and hope it won’t fail again, that’s still time lost for every failure (involving manual intervention to review, decide to re-run and make the decision to ignore it if the second run passes).
Flaky tests undermine confidence in testing accuracy
Unfortunately, a common reaction to flaky tests is:
It’s a problem with the test, not my software. If I rerun the test, maybe it won’t fail in the next run.
Flaky tests cause inconsistencies in test results which, in turn, can cause developers to lose faith in the tests themselves. A 2019 ACM ESEC/FSE research paper entitled Understanding Flaky Tests: The Developer’s Perspective looked into the impact of flaky tests on developers. The research found that the less reliable developers perceive test output to be, the more likely they are to completely disregard the outcomes of test results. In short, developers simply don’t trust test results.
A team that loses confidence in their tests is in no better position than a team with 0 tests. There is no point in testing for something if the results are going to be ignored.
Aside from the negative impact on the development team, these unaddressed failing tests could turn into ticking time bombs waiting to blow up on customers’ laps.
Unaddressed flakiness introduces expensive technical debt
Flakiness needs to be fixed promptly, or else technical debt is accrued, and ‘interest repayments’ become increasingly expensive as the flakiness spreads and creates more flakiness.
In other words, if developers are in the habit of rerunning, hoping to get lucky next time, then new flaky regressions will go unnoticed and the stability of the overall system degrades over time. Failing tests can no longer be tied to a particular commit. It is extremely difficult to come back from this point.
Flaky tests are incompatible with CD (or any reliable release process)
Flaky tests prevent any kind of reliable release process. If there are many flaky tests, then a clean run almost never happens, and human judgement will be required to know whether a release can be made. The more flakiness in the system, the more likely that judgement will be to hold back a release unnecessarily while flakiness is worked through. Or worse, products get released prematurely – if your tests are never clean then there will always be some failures tolerated and these could be serious. This is a large part of why 82% of software companies report production failures related to unresolved failures in test.
Resolve flaky tests with time travel debugging
It doesn’t matter whether it’s the codebase or the test that’s flaky. It needs to be resolved; and the longer you leave it, the harder it will get. Think of flakiness as our target virus, that must neither be allowed to multiply nor mutate.
Time travel debugging is a key ingredient in reliably and efficiently resolving flaky tests.
Automate the recording of flaky test failures
When part of Continuous Integration / test automation frameworks, time travel debugging can be used to continuously run flaky tests under recording. The recording captures an exact replica of the failing run and provides a complete picture of what the program did, and why. All engineers have to do is to debug the recording forward and backward – just like with a video player – to rapidly locate the root-cause of the issue. The ability to time travel through code execution, both forward and backward, is called time travel debugging.
This record/replay process significantly improves engineering efficiency, since no time needs to be wasted trying to reproduce the failure.
Flaky tests tend to fail in a different way each time, and so without time travel debugging it is difficult to gather enough information about a single failure. Worse still, the root cause of an intermittent failure often occurs some time before the effects are noticed, e.g. the data corruption happens a long time prior to the assertion failure. Having a recording of a failure allows engineers to easily determine the root cause of the bug from a single run – winding back and forth, quickly homing in on the problem.
Make bug fixing predictable
Due to their intermittent nature, it can be impossible to predict how long it will take to fix a flaky test. But with time travel debugging, the recording captures everything (down to instruction level) needed to debug and fix the issue – making defect resolution a whole lot more predictable.
Reduce schedule delays
When software is shipped late, more often than not, it is because the developers cannot get the bugs out. With Time-To-Resolution of flaky tests significantly reduced, and increased levels of predictability in debugging, schedule delays can be minimized.
Maintain stability
One of the worst implications of unreliable test suites is that it is often impossible to notice newly introduced intermittent failures. When you have a test suite you can trust, it quickly becomes obvious when a new source of intermittent failures creeps in, even if it causes the test suite to fail only occasionally.
With time travel debugging as part of your CI or test automation framework, regressions are quickly spotted, and the bad code can quickly be rooted out.
How to fix flaky tests in your CI pipeline
Undo is an enterprise-grade time travel debugging platform – specifically designed for Linux C/C++ and Java applications. It offers the most efficient solution for fixing test failures, including flaky tests.
The illustration below shows where Undo can integrate into a modern CI pipeline.
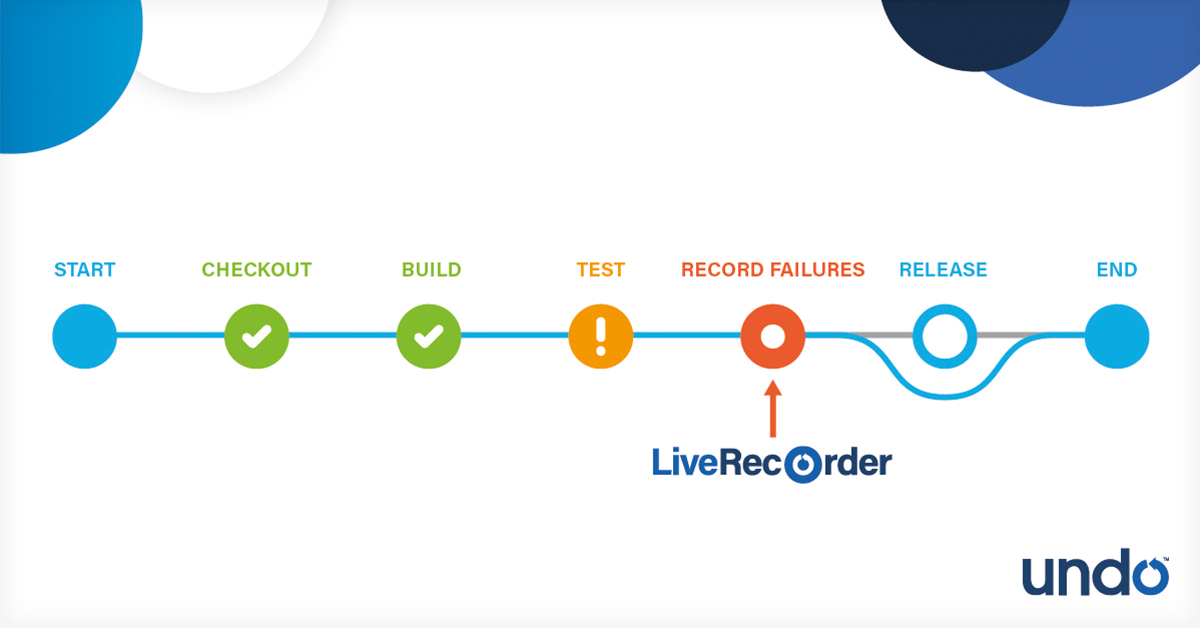
Some engineering teams decide to take flaky tests out of their automated test suite into quarantine. For example, if it fails 3 times within 2 weeks, it’s a flaky test and it gets pulled out of the delivery pipeline and added to a ‘sporadic tests farm’. Only when that test has proved itself stable, will it be reintroduced into the delivery pipeline. Although test coverage is temporarily lost, this quarantining strategy prevents disruption to the CI/CD pipeline.
As part of the quarantining, Undo can be used to continuously run the tests in the sporadic tests farm in a loop, under recording until they fail. Once they fail under recording, engineers have everything they need inside those recordings to quickly diagnose the problem. Top tip: run the tests repeatedly and record as much as you can (product code and test code).
Or, if preferable, intermittently failing tests can be tagged as such and always run under recording while leaving them in the main suite so that coverage is not lost. When the tests fail again, you then have a recording.
Either way, it’s a huge win.
This video illustrates how Undo can be used to rapidly resolve intermittent failures in a ‘sporadic test farm’ scenario.
Summary
Flaky tests result in unproductive software teams and unreliable software releases.
It can be an expensive and painful process to fix all the flakiness; but the longer the problem is left unresolved, the more of a drag on productivity and product quality it becomes, and the more expensive it becomes to fix too.
Time travel debugging transforms software failure resolution from a slow and unpredictable process of elimination into a systematic, repeatable workflow.
- Make bug fixing predictable and avoid schedule delays
- Accelerate defect resolution and boost developer productivity
- Boost CI/CD pipeline efficiency and reduce engineering costs
Undo enables development teams to capture intermittent defects in a recording, allowing them to rapidly investigate and resolve flaky tests.
Want to see how this could work in your environment? Try Undo for free.