
Resources
ARMv9 Support in Undo 9.0
In a coincidental but pleasing alignment of version numbers, the new version 9.0 of the Undo Suite introduces (among other features) our first support for the constantly expanding capabilities of ARM v9.0 architecture CPUs.
Since the first introduction of ARM v8-A, ARM has introduced new versions of their 64-bit architecture on roughly an annual basis. This is considerably more frequent than the rate at which x86 processors have been gaining more features! These updates add new instructions, behaviors, extra modes and more. But most software just runs on these newer CPUs without any special intervention; why is it necessary for Undo to add particular support for specific versions of the architecture?
The answer lies in the nature of what the Undo Engine needs to do in order to achieve deterministic replay of applications, which is essential to time travel debugging. The first time every instruction of an application is run, we examine it in order to determine whether it can possibly have any non-deterministic effects, and if so we arrange to record those effects in the event log every time it is executed. This means we need complete visibility of what every instruction could possibly do, so CPU-specific support is very important.
In this article we’ll describe some of the new ARM architecture features that were interesting to implement, explaining what we did and how you may benefit from using them in your applications.
Scalable vector extension 2
ARM v9.0-A introduces version 2 of the Scalable Vector Extension (SVE2). Vector registers are bigger than the normal general registers, not to hold larger values but rather to hold multiple elements of normal types, allowing the CPU to perform operations over a large amount of data by processing parallel items at the same time. SVE adds several extra capabilities over ARM’s previous Neon 128-bit vector architecture, such as per-lane predication, gather-load and scatter-store.
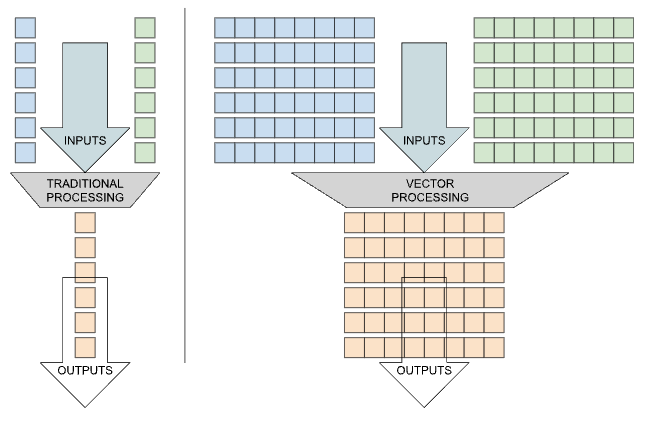
SVE was focused on HPC scientific computing workloads, to process the immense amounts of data collected in areas such as meteorology, astronomy, quantum physics, fluid dynamics, and pharmaceutical research. SVE2 adds more kinds of data-processing instruction, providing opportunities for a wider scope of applications to benefit from vectorization. In particular, ARM added fixed-point data operations, widening and narrowing conversions for 8-, 16-, and 32-bit data types, which are expected to benefit multimedia and machine-learning programs. Additionally, there are optional specialised instructions for a number of cryptographic algorithms.
We added support for the Scalable Vector Extension in Undo 8.1.0, and the extra instructions in SVE2 did not pose too much of a challenge to our instrumentation, but some of the first widely-available CPUs implementing SVE2 do have an aspect that is worth highlighting: the Graviton 4 CPU has shorter vectors than its predecessor the Graviton 3.
Whereas Intel’s instruction set extensions have tended to add a new set of instructions for each different size of vector registers (e.g., AVX-512 extends the x86 instruction set to process data in vectors that are exactly 512-bits long), ARM has taken a vector-length agnostic approach meaning that the same application will, without modification, run on CPUs with vector registers that are 256-bits, or 512-bits, or even longer, and in each case can make efficient use of those vector registers: performing fewer or more iterations through data-processing loops in order to process all the necessary data in vector-length sized chunks.
In the case of Graviton 4 (or more precisely, the Neoverse-V2 core that powers it) they have added the new capabilities of SVE2 but have chosen to implement them on shorter 128-bit vector registers than the previous Neoverse-V1 core, which is in Graviton 3 and has 256-bit vectors. Most applications will not be functionally affected by this, except in the speed that they can process their data. But it affects Undo’s ability to replay recordings of applications on CPUs other than where they were recorded, because we expect each instruction to operate on the same amount of data at record and replay time (i.e. we will not attempt to run a different number of iterations through the data-processing loops).
So, after recording on Graviton 4 a program which uses SVE2 instructions, it is easy to see that attempting to replay it on Graviton 3, which doesn’t have those instructions, will not be possible. But also, after recording on Graviton 3 a program which uses SVE instructions, it is more surprising that attempting to replay it on Graviton 4, which does have those instructions, will equally not be possible because of its shorter vector length.
If doing this would be important for your application, there is a workaround which potentially will meet your requirements. That is, if at record time it is arranged for the program to use only 128-bit vectors and SVE instructions, then it will be able to replay on either CPU. One way to do this is to write the requested vector size (represented in bytes, so in this case 16) into the kernel file /proc/sys/abi/sve_default_vector_length before launching the program that is to be recorded.
To handle these compatibility issues automatically, you should use the Undo Replay Service, and provision suitable machines with the required vector length and other features required to replay your application. Please contact Support to find out more.
Branch target identification
Branch Target Identification (BTI) is a feature added to ARM v8.5 to help protect applications against various types of hacking attacks.
Consider an application with a buffer overflow vulnerability: if that buffer is near the call stack, then the attacker may be able to control the address of the next instruction to be executed after the current function returns. If the vulnerable buffer is in a page without execute permission then they cannot just write new instructions and run them, but by carefully choosing addresses a few instructions before the end of a legitimate function, they can execute small state changes. This is known as Return-Oriented Programming (ROP), and by chaining together such sequences, the attacker can in effect execute arbitrary logic.
BTI mitigates against this by preventing the CPU from branching to instructions that were not intended to be reached by an indirect branch. When the application is built, the compiler adds a new instruction, BTI, to all addresses that represent real code entry points (e.g. the start of a function call). All existing ARM CPUs without the feature will ignore the new instruction, so it is safe to start adding them to applications even if you don’t know where they will be run. But if the feature is enabled, then any time there is an indirect branch in the program (such as a switch statement) the CPU raises an exception if there isn’t a BTI instruction at the destination. This significantly reduces the opportunities for attackers to be able to represent their logic using side-effects of the real program code.
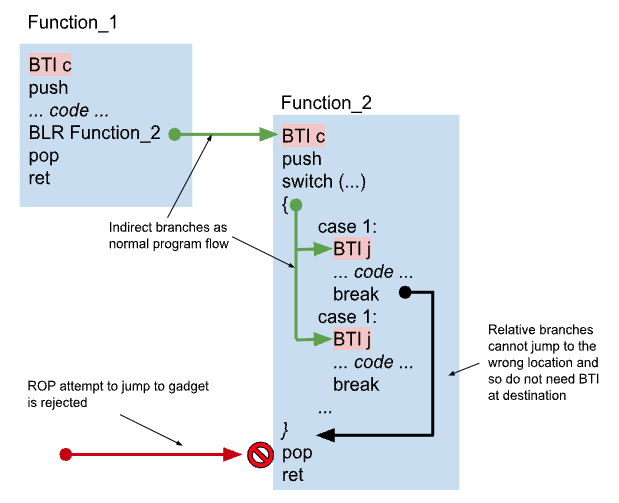
Because the Undo Engine instruments application code before executing it, we run a modified copy of every function and it is located at a different address than the original code. Finding the address of the modified code can be significant work, so this is separated out into a shared function which is used for all relative jumps. When we eventually jump to the modified code, it is not generally convenient to use precisely the same instruction as existed in the original function. The effect of using a different type of jump instruction is that PSTATE.BTYPE on reaching the destination, may be different when running inside Undo Engine compared to its value when the application is run natively.
The value of PSTATE.BTYPE is not generally visible to the program, although it can be observed in the debugger registers view, (and, rarely, if a signal is delivered at precisely that time, the signal handler can potentially examine the saved PSTATE that is recorded in the signal stack frame). However it does mean that the CPU could reject some of our indirect jumps because the jump type doesn’t match the BTI instruction at the destination. In order to get around this, we don’t currently enable the BTI feature in our translated code (BTI can be enabled or disabled on a page-by-page basis).
The upshot of this is that programs which enable the BTI feature are able to run inside the Undo environment, but there are currently a couple of limitations. Firstly, if the application doesn’t contain BTI instructions in the right places, and so would crash when run natively, it will generally still run fine under Undo and we would not observe that failure. (We think it would require some fairly unusual circumstances for this issue to arise, but it’s possible if an application is generating code at runtime). Unfortunately, also the recorded application would not get BTI’s benefits of hardening against attackers; this shouldn’t be a major problem for debugging sessions or integrations into CI workflows, but it may be relevant if Undo is being used to record your application within a potentially hostile production environment. If you have concerns about this, please contact support.
Cross page size replay support
One interesting feature of ARM’s 64-bit architecture is that the translation granule, or smallest page size, is not fixed at 4k (as it is in x86) but can be configured by the operating system to either 4k, 16k or 64k. An operating system must maintain page tables: descriptions of how each application’s virtual memory space maps onto the physical memory of the CPU. Larger page sizes mean that the number of page table entries is smaller, meaning that the OS can manage them more efficiently and also that the CPU (which buffers a certain number of entries) can get more of the workload’s page descriptions from the buffer instead of having to examine memory.
In previous versions of Undo, we had required that the page size on the CPU replaying a recording had to be the same as the page size on the CPU where the recording had been made. This is because we need the layout of accessible memory pages during replay to precisely match the layout at the time of recording, so that any instructions accessing memory will get the correct values.
Consider a program which allocates memory (as many do), and at record time the operating system was using a 16k page size, and mmap() returned a page starting at 0xFFFF4000. If we tried to replay this on a CPU using a 64k page size, if we ask the operating system to allocate a region starting at exactly 0xFFFF4000 then it will not be able to do that for us, because the address is not divisible by 64k.
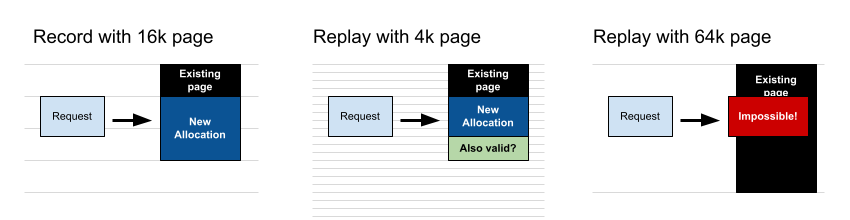
What is less obvious, are similar problems in replaying on a smaller page size than was in use at record time. If the application is running on a CPU with 16k pages, and requests a region of length 20k, then mmap will return a region that is 32k in size. The application could quite validly access the whole of that 32k region. Whereas if we replay the same mmap system call on a CPU with 4k pages, then the operating system will allocate a region that is 20k in size, and any attempt to access the following 12k would rightfully fail. For simplicity, we disallowed that case.
However, not all the page size choices are available on all actual CPUs. We had heard from some customers making recordings on 16k page size, but the CPUs where they wanted to replay only supported 4k pages. In any case, even if hardware support is available, we have found it difficult to obtain images of Linux distributions configured to use 16k pages.
In this version of UDB, we now alter the arguments to system calls such as mmap and mprotect during replay, so as to request the OS to modify regions of a size that always matches the size which would have been affected at record time. This means we can now fully support replaying on CPUs with a page size less than or equal to the page size in use at the time of recording.
Tracking usage of ISA extensions
One very common way that customers use the Undo Suite, is to record an application in one environment, and replay it in another. For example, a developer might have an application which runs on an embedded device to which access is restricted in some way, and has only limited time available; but once a recording is generated, it can be brought back to the developer’s laptop and debugged at leisure. Often, though, the developer has an x86-based laptop, so recordings of ARM CPUs need to be replayed remotely. Undo’s Replay Service makes this happen almost transparently, but in order to select a suitable CPU to replay on, it is important to be able to determine what is required to replay a given recording.
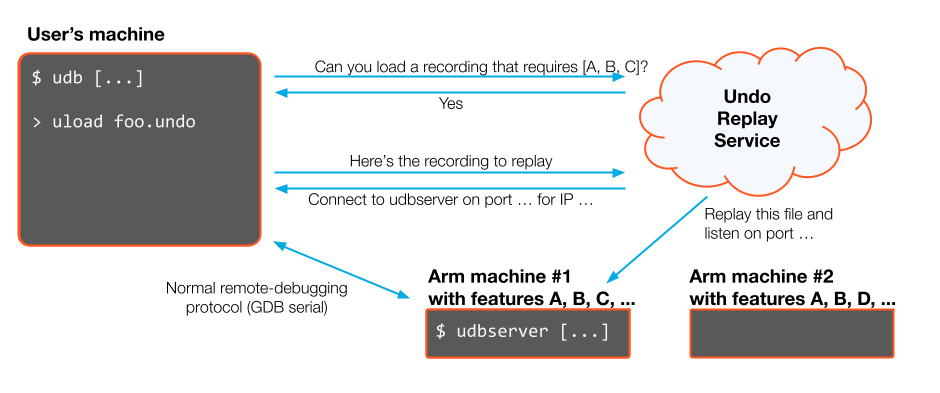
Where we are adding support for new Instruction Set Architecture (ISA) extensions, we are also keeping track of which of them are actually used by the application. This is possible because we examine every instruction before the first time it is executed, a process called just-in-time (JIT) instrumentation. Information about what instructions have been used is stored in a header of the recording, isaexts, which has been present for some time for x86 recordings but now is populated in arm64 recordings as well.
This means that if your application doesn’t use instructions from, say, the sm3 crypto extension, then we know that we don’t need to have that extension present on a machine in order to be able to replay there. This can be important because many ARM ISA extensions are optional, and availability varies among products: newer CPUs are not necessarily supersets of older ones, even from the same manufacturer.
In the case of our developer’s embedded device application: if replay were to require precisely the same CPU characteristics as on the recording machine, it may only be possible to replay on the inconvenient and highly contended platform; but as we can be more flexible about CPU capabilities, in fact we can normally replay on more convenient and abundant cloud servers.
Please note that we have not, at this point, fully annotated the decoder for ARM instructions that were already supported in previous versions of the Undo Engine, e.g. fp, asimd, fcma, etc. For any extensions that are present on the machine where recording took place, but we don’t (yet) track the usage of, we take a safety-first approach and register them in the isaexts header to indicate that they at least might have been used.
If you find that in your environment, you are unable to replay recordings because one of these extensions is not available on the replaying machine, then please contact support for assistance in making replay work seamlessly.
Looking ahead to future versions
ARM architecture versions 8.5 and 9.0 are by no means the end of the road. ARM’s public documentation describes versions up to 8.9 and 9.6 at the time of writing, and there is no reason to think that the annual increments will stop! But there is some time to wait, possibly years, before there is general availability of CPUs which implement these features, or widespread usage of new features in operating systems and applications.
Each feature requires explicit support to be usable within Undo Engine (some more work than others, of course) so we need to consider where we spend our engineering time. In general we aim to keep up with the feature set that is available in Graviton CPUs. But we do also consider customer feedback to ensure we keep up with the platforms they use, so if an upcoming extension is going to be important for you and your applications then please let us know through the usual means.
Every environment is slightly different, and some may need additional work. This is especially true where there are CPUs from other vendors, because of differences in cryptographic signing algorithms for pointer authentication, SVE vector length, extension availability, and so on. But much of this can be mitigated with instruction set extension tracking and mechanisms like cross page size replay support. Even in heterogeneous setups, our aim is to ensure that the Replay Service means you will always be able to play back your recordings without having to worry about any of these differences.